
출처가 명시되어 있지 않은 모든 이미지의 지식재산권은 재단법인 네이버 커넥트에 귀속됩니다.
Conditional generative model
Conditional generative model
- 어떻게 보면 언어번역 모델처럼 생각해도 된다.
- 특정 조건이 주어졌을때 해당하는 결과가 나오는 모델이다.
- 기본적인 Generative model은 영상이나 샘플을 생성해낼수는 있지만 조작할수는 없었다. - random sample에서부터 모델링을 한다.
- 반면에 Conditional generative model 은 유저의 의도가 반영되는 모델이다.

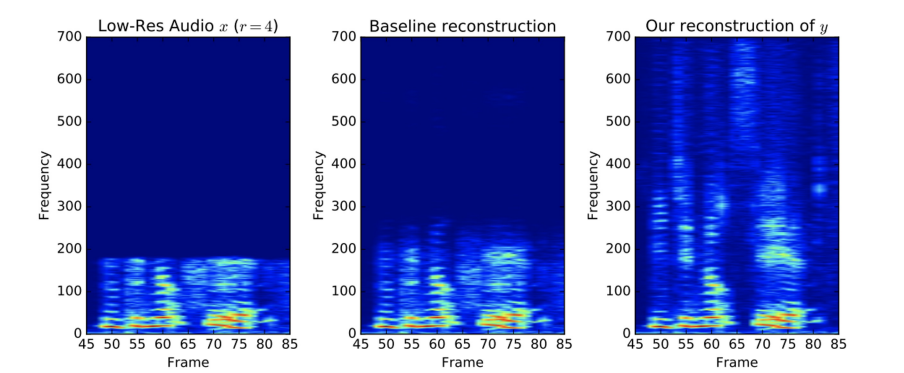
Example of conditional generative model - audio super resolution
- 저 퀄리티의 오디오를 고 퀄리티의 오디오로 올려주는것도 해당한다.
- 한자로 주어진 언어를 영어로 번역하는 모델도 해당한다.
- 제목만 주고 나머지 내용을 만들어가는 뉴스기사 작성 모델도 있다.


Recap: Generative Adversarial Network
- 위조 지폐범이 생성 모델이고 이 범인이 가짜 데이터를 만들어낸다.
- 경찰 역할을 맡은 Discriminator가 진짜 가짜를 구별하는 판별사 역할을 해낸다.
- 학습이 진행될때 범인(생성모델)은 경찰이 위조지폐를 검출하지 못하게 적대적으로 학습하고 반대로 경찰(Discriminator)는 위조지폐가 왔을때 더 잘 찾아내기 위해 학습하면서 Discriminator의 성능이 높아지면 Generator의 성능도 같이 높아지게 된다.

(Basic) GAN vs. Conditional GAN
- 기존의 GAN은 아래와 같이 Generator의 입력으로 랜덤 코드 z를 넣고 Fake data가 생성이 되면 Descriminator로 판별한다.
- Conditional GAN 모델은 c 라는 Conditional 정보를 넣어주는 부분이 존재한다.

Conditional GAN and Image translation
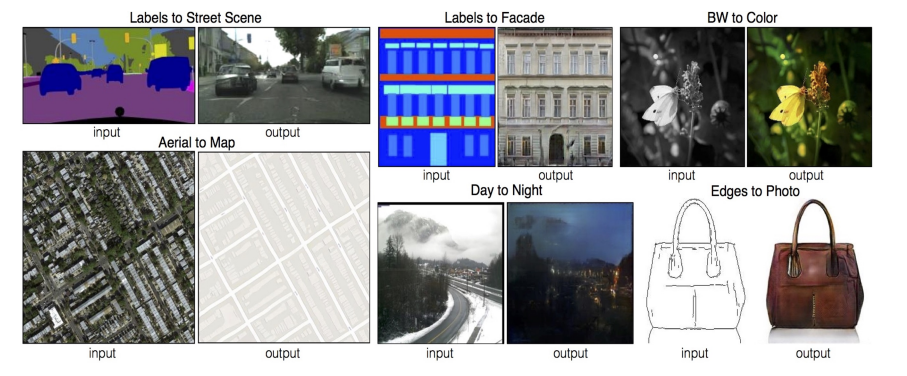
Image - to - Image translation
- 인풋 이미지가 들어오면 여러 스타일로 바꿔주는 Style transfer , 고해상도로 만들어주는 Super resolution, 오래된 흑백 사진을 칼러 사진으로 만들어주는 Colorization등 많은 응용 사례가 있다.

Example: Super resolution
Example of conditional GAN - low resolution to high resolution
- 입력으로 저해상도의 이미지가 들어오면 고해상도 이미지로 출력을 해준다.
- 입력으로 저해상도 이미지가 주어지면 Generator에서 가짜 고해상도 이미지가 출력된다.
- 리얼 데이터로는 고해상도의 이미지를 주어서 판별기가 실제 고해상도 이미지와 비슷한 특성을 따르는지 판별한다.

이런 Super Resolution 을 꼭 Conditional GAN으로 풀어야만 하는건 아니다.
Difference between regression and conditional GAN for SR
- 이전에는 CNN 구조를 활용해서 SR을 할때 더 단순한 loss를 사용해서 진행했다.
- 주로 MAE(L1), MSE(L2) loss를 사용했다.
- 이런 구조를 regression model 이라고 한다.

Comparison of MAE, MSE and GAN losses in an image manifold
- MAE loss는 ground truth와 생성된 영상이 주어 졌을때 그 두개사이 오차의 절대값 평균을 측정한다.
- MSE loss는 오차 제곱의 평균을 측정한다.
- 해상도는 높아지는거 같지만 굉장히 블러처리가 되어있는듯한 이미지를 얻게 된다.
- 왜냐하면 pixel 자체의 intancity 차이를 이용하는데 평균 에러를 구하다 보니까 출력 결과와 비슷한 에러를 가지는 많은 패치들이 존재하게 된다. 때문에 구분성이 떨어지게 된다. 또한 적당하게 거리가 떨어진 이미지를 생성하는게 편하게 모델이 답을 내버리는 해결책이 되어버린다.

Meaning of "averaging answers" by an example
- 이미지를 Colorizing하는 단순한 예제이다.
- Real Image로는 흰색, 검색밖에 없는 극단적인 예를 들도록 하겠다.
- 입력 이미지를 넣어주고 L1 loss를 이용해서 학습하게 되면 회색 이미지가 나오게 된다.
- 하지만 GAN을 사용하게 되면 이런 경우가 잘 발생하지 않는다.

Image translation GANs
Pix2Pix
Task definition
- Image translation은 한 이미지 스타일을 다른 이미지 스타일로 변환하는 걸 의미한다.
- 일반적으로 입력 해상도와 출력 해상도가 같게 나온다.
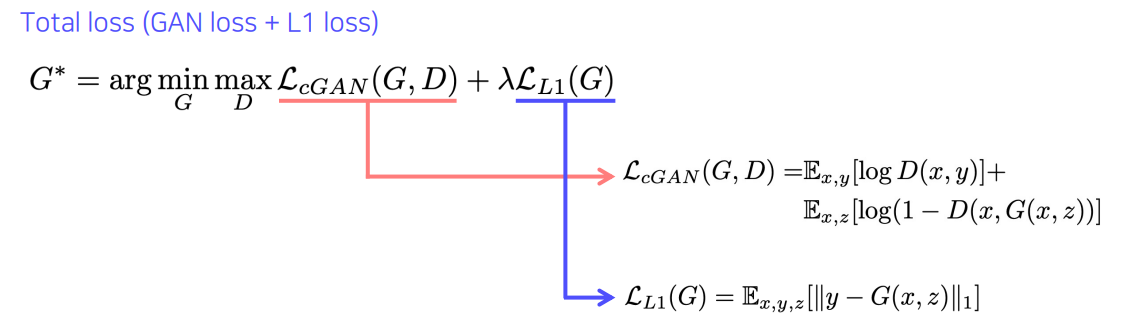
Loss function of Pix2Pix
- Pix2Pix에서는 Loss fuction을 아래와 같이 정의해서 쓴다.
- MAE loss가 블러한 이미지를 만들지만 적당한 가이드로 쓰기에는 좋다. 여기에 GAN loss를 더해서 Realsitc한 출력을 만들도록 해준다.
- 여기서 MAE loss를 쓰는 이유는 두가지가 있다.
- GAN loss만 쓰게 되면 입력된 두개의 페어 (x,y)를 독립적으로 비교해서 real이냐 fake이냐만 판별하기 때문에 y와 비슷한 결과를 만들어 낼 수 없다.
- 최근에는 GAN만 가지고 학습하는게 많이 안정화 되었지만 예전에는 그렇지 못했다. 때문에 L1 norm으로 가이드를 주어서 학습이 안정적으로 이루어지게 했다.
- 이전의 모델들과 또 다른 차이점 이라면 G에 z뿐만 아니라 x도 들어간다는 점이다.
Role of GAN loss in Pix2Pix

CycleGAN
CycleGAN
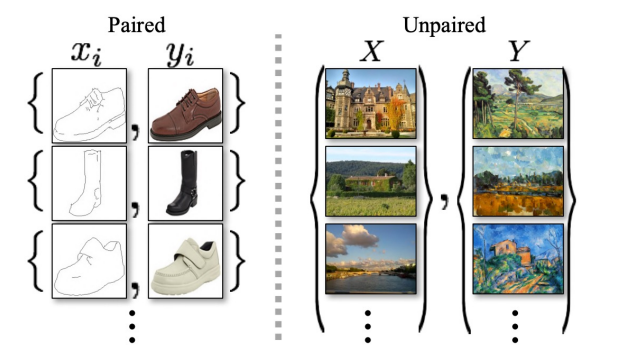
- Pix2Pix 기법은 supervised를 사용했기에 "pairwise data"가 필요하다.
- 하지만 이런 pairwise data를 항상 얻는것은 어렵거나 불가능하다.
- 이 문제를 해결한것이 CycleGAN이다.
- 도메인 간의 translation을 두개의 set데이터 집합만으로 학습하게 하는 방법이다.

Loss function of CycleGAN
- CycleGAN loss는 GAN loss와 Cycle-consistency loss를 결합해서 사용한다.
- 여기서 싸이클이라는 얘기처럼 결국엔 방향성이 있다. X -> Y 로 가는 방향과 Y -> X로 가는 방향을 동시에 학습진행시킨다.
- Cycle-consistency loss: 이미지하고 그게 트랜스레이션 된 결과하고 다시 돌아왔을때 원본이미지와 동일해야 한다는 loss를 의미한다.
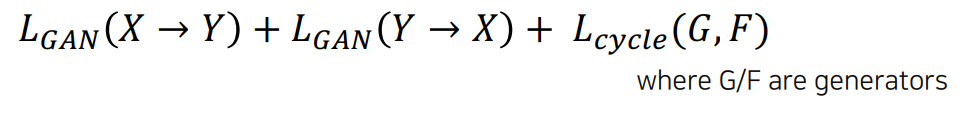
Gan loss in CycleGAN
- Gan loss는 translation을 하게 된다. 즉 X 에서 G를 통해서 Y로 가서 생성이 되면, 그게 정말 Y같은지 $D_Y$를 통해서 판별을 하게 된다. 다음에 Y에서 F를 통해 X로 갔을 때 정말 X의 스타일 같아 보이는지 $D_X$로 판별한다.
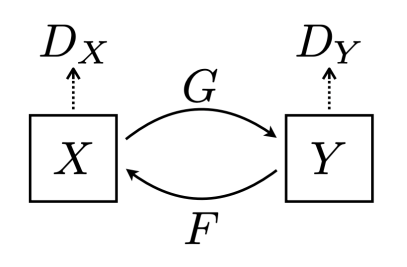
If we solely use GAN loss ...
- 만약 GAN loss만 사용하게 되면 Mode Collapse에 빠지게 된다. ( Mode Collapse란 인풋에 상관없이 하나의 아웃풋만 계속 출력하는 형태를 말한다. )
- 최적화에서 Local minimum에 빠지는 형태와 비슷하다고 볼 수 있다.
Solution : Cycle - consistency loss to preserve contents
- 위와 같은 문제를 해결하기 위해 등장했다. ( 모델 안의 스타일 뿐만 아니라 contents도 유지를 해야한다.)
- X에서 Y로 가고 Y에서 변환된 이미지를 다시 X로 간다. 이때 이게 차이가 있으면 안되고 원본이 복원되야 한다.
- 이 방법을 X에서 Y로 갈때, Y에서 X로 갈때 양쪽에 다 사용한다.
- 이 과정에서는 어떠한 Supervision도 들어가지 않는다. (Self - supervision 과정)

Perceptual loss
Gain is hard to train
- Alternating traing이기 때문에 어렵다. argmax와 min을 번갈아가면서 왔다갔다 한다.
- 다른 high - qualiy image를 얻는 방법은 없을까? preceptual loss로 가능하다.
Perceptual loss, yet another apporach for achieving high quality output
- GAN loss ( adversarially loss )
- 트레이닝하기 어렵고, 튜닝이 필요하고, 코딩이 더 필요하다.
- 대신에 어떠한 pre-train networks도 필요하지 않다.
- 다양한 application에 제약없이 사용이 가능하다.
- 하지만 data에 dependency가 생기게 된다.
- Perceptual loss
- 학습하기 편하고, 코딩하기도 편하다.
- 대신에 pre-train networks가 필요하다.
Perceptual loss
- Pre-trained classification model의 filter를 보면 filter의 response 그리고 filter 자체의 형태가 human의 visual perception에 해당하는 그것과 굉장히 유사하다는 관찰들이 있었다. 이런 perceptual space에서 "우리가 눈여겨 봐야할것과 그렇지 않은것을 구분할 수 있지 않을까?" 라는 의문이 Perceptual loss의 시작점이다.

GAN을 사용하지 않고 Perceptual loss만을 사용해서 Style transfer를 학습시킬수 있다.

이제 Perceptual loss를 사용해서 학습하는 방법에 대해서 살펴보겠다.
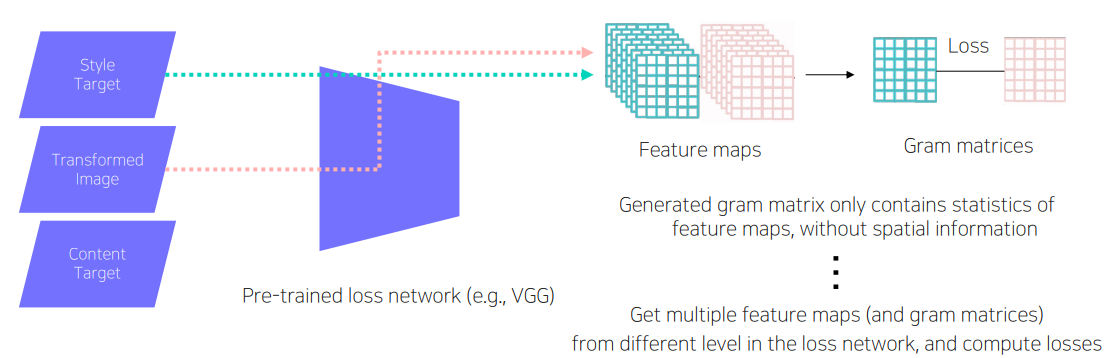
- 먼저 Image Transform Net은 이미지가 주어지면 원하는 하나의 스타일로 트랜스폼을 해준다.
- Loss Network로는 우리가 학습된 loss를 측정하기 위해서 VGG model을 사용한다. 그리고 feature를 중간중간에 다 뽑아준다.
- Style Target과 Content Target을 이용해서 loss를 measure하게 된다.
- 특징으로는 Loss Network는 pre-trained Network를 사용하고, training하는 도중에는 fix되어 업데이트 되지 않는다.
- backpropagation은 가능하지만 Loss Network를 업데이트하지 않고 Image Transform Net을 업데이트하여 학습시켜준다.
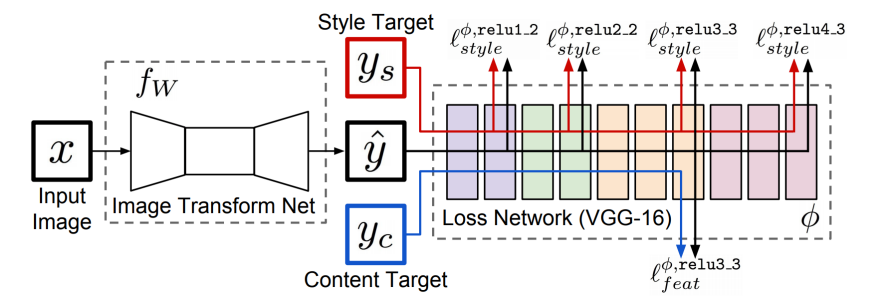
Feature reconstruction loss
- Stype target 과 Content Target 두가지를 통해서 loss를 측정한다.
- X에서 부터 Y^ 을 생성해낸다. 이 Y^이 우리의 의도대로 생성해내기 위해서 VGG로 feature를 뽑게 된다. 이때 Content Target이 처음 Content를 잘 유지하고 있는지 판단해주는 loss가 Feature reconstruction loss 이다.
- 그래서 Content Target에서는 변형하지 않은 원래의 X를 넣어주는게 일반적이다.
- 이 두개를 비교할때는 간단하게 L2 loss를 사용한다.

Style reconstruction loss
- 변형하고 싶은 style의 이미지를 Style Target에 넣어준다.
- 여기서도 마찬가지로 Style Target 이미지와 Transformed Image를 VGG에 넣고 Feature를 뽑는다.
- 여기서 중간에 Convolution Feature Map을 출력을 하기 때문에 Tansor형태로 뽑히게 된다.
- 그대로 Feature map을 비교해서 loss를 측정하는것이 아니라 style을 담기위해서 Gram matrices를 수행한다.
- Gram matrices는 Feature Map에 공간적인 특징이 없는 통계적인 특징을 담기위해 디자인 되었다. sumation을 통해서 Pooling을 해서 desgin한다.
- 중간중간 여러 다른 level에서 style loss를 측정한다.
Various GAN applications
Deepfake
Deepfake
- 사람의 얼굴만 생성하는게 아니라 목소리도 생성하게 되고 목소리를 따라 얼굴의 모양도 변하게하는게 가능하다.

Face de-identification
Face de-identification
- 사람의 얼굴을 약간의 변형을 통해서 인지를 저해시키는 모델이다.

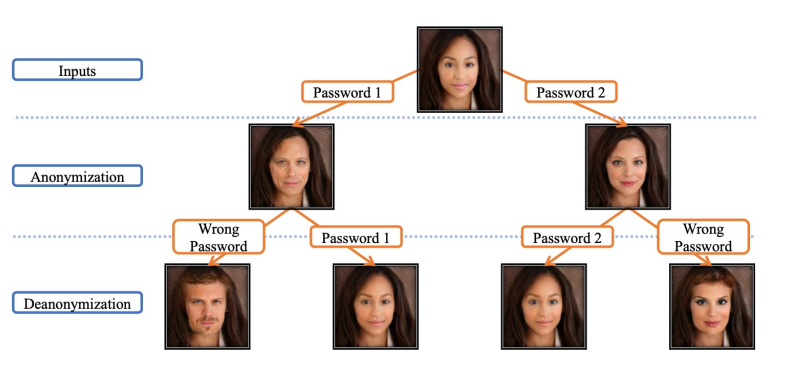
Face annonymization with passcode
- password를 제대로 입력했을때만 원하는 이미지가 나오고, 그렇지 않은 경우에는 다른 이미지가 나오도록하는 모델이다.
Video translation (manipulation)

'Deeplearning > Computer Vision' 카테고리의 다른 글
| [Computer Vision] 03. Image classification (0) | 2023.03.30 |
|---|---|
| Computer Vision 9. Multi-modal (0) | 2022.10.21 |
| Computer Vision 7. Instance Panoptic Segmentation (0) | 2022.10.19 |
| Computer Vision 6. AutoGrad (0) | 2022.10.19 |